And without using scientific measurement at what point do you infer that the inference of DLSS - even when guessing wrong - is superior to native if we take your suggestion to full conclusion?
We had an entire PS3/360 generation where DF couldn't identify a broken sRGB gamma conversion on the 360, or missing exponent fog and had everyone believe the opposite of scientific measurement, so having lots of people parrot something that has no scientific basis to back it up is not new in gamer "trust me bro" land.
The reason why empirical measurement is necessary is because the size of the problem domain is beyond definition, and despite the thousands of images and opinions, we have no way of know how it will infer the next situation. just say it started inferring genitals on characters, when it was just supposed to be an outline, a little like my first hand experience with a Trolls film soundtrack getting inference that recovers the mixed out f### word in a track, multiple times despite the album being from a kids film.
Without measuring and sampling the error rate you cannot say that DLSS will perform better on all new games based on your visual preference for how it "looks" on games you've experienced now. That needs numerically backed and justified.
Are you using chatGPT? You read like a caricature of an autistic Sheldon. By your same conclusion, FSR can never be proven to perform better than XeSS or DLSS, no matter the iteration. Bravo.
Meanwhile
Manages to be 50/50 better than native according to
AMD unboxed, errr, hardware unboxed.
That's with the game's version of DLSS implementation. The DLSS swapper can basically make it 100% in favor of DLSS over Native.
All your mumble about architecture superiority on AMD side is bullcrap. The RT blocks are simplified on AMD side but they do not participate at computation while idle. Nvidia made huge strides since Turing to actually make the tensor cores / RT cores asynchronous with the shader pipeline. AMD's Hybrid approach is, exactly as per their patent, supposedly to simplify and save on silicon area, for more rasterization.
Seems like a fine engineering decision right? Right? I'm an engineer, and that would fully make sense if it were brought up as an alternative.
Yet here we are, a 4080 with 379 mm^2 competes with a 7900XTX's GCD 306mm^2
- With 20~25% of silicon dedicated to RT/ML
- Without taking into account the memory controllers (how much you want out? 150~190 mm^2?)
- Without taking into account the huge cache upgrades Ada got. How much area, who knows, but cache is typically not space savy.
I removed the MCDs on RDNA 3, which includes the cache, just to showcase how stupid this architecture is. You're left with nearly a raw GCD chip of 306mm^2 of pure hybrid RT/ML to optimize the area towards more rasterization, as per patent.
Yet we're talking a 2~4% RASTERIZATION performance difference for nearly a 60W more power consumption advantage on AMD side. When you go heavy RT it goes to shit on AMD side.
RT’s solution on AMD already is super heavy on cache and latency and queue ordering. Sprinkling ML on top of that + shader pipeline is a big no no as of now.
Everything has to be scheduled inline on AMD side. Anything chaotic like path tracing is a big nope with that architecture. Anything with too much dynamic shaders and inline craps the bed too and becomes slower than DXR 1. RDNA's 2 synchronization barrier prevents GPU from using async work to keep execution units busy while the BVH is in the compute queue. This has very poor occupancy when it happens and is latency bound. L2 latency is likely to be a limiting factor when building the BVH, because when occupancy is poor, L0/L1 cache hitrates are also poor. This has been micro benched.

Our testing also shows that the RX 6900 XT’s L2 cache has a load-to-use latency of just above 80 ns. While that’s good for a multi-megabyte GPU cache, it’s close to memory latency for CPUs. In the end, the 6900 XT was averaging 28.7 billion box tests and 3.21 billion triangle tests per second during that call, despite being underclocked to 1800 MHz. AMD says each CU can perform four box tests or one triangle test per cycle, so RT core utilization could be anywhere from 7.2% to 29% depending on whether the counters increment for every intersection test, or every node.
Ultimately, i don't even need to pull up graphs to explain how you're wrong about the superiority of AMD's arrchitecture, because we go back to basics : HOW IN THE WORLD is AMD not crushing Nvidia into dust in rasterization after their hybrid approach? uh? Before you run off to chatGPT, you have to answer that basic question.
What Nvidia managed with a 379mm^2 silicon vs 529mm^2 is a monumental schooling on architecture. The ASIC nature of the RT is not a problem apparently, for all the surface area it gobbles up, it leaves rasterization room to compete against AMD and when fully utilized in heavy ray tracing, it simply bitchslaps the hybrid approach. Your arousal on architecture optimization falls flat on its face if the optimization path taken didn't give a crushing victory. Its basic engineering. They have to go back to the drawing board.
Back to topic,
Speaking of the DLSS swapper, the upscaler for 3.5.0 looks nuts
That's the upscaler only, nothing to do with ray reconstruction yet. They made the upscaler, which was already the best, even better by a huge margin. Mind blowing.
Asking for scientific evidence to prove that DLSS is better then FSR is the same as asking for scientific evidence that water is wet. Sure you can request it, but it's obvious that it is.
BuT WhAt aBoUt tHe sIgNaL To nOiSe rAtIo? i lEaRnEd a fEw tErMiNoLoGiEs oF SiGnAlS At sChOoL, lOoK At mE MaMmA













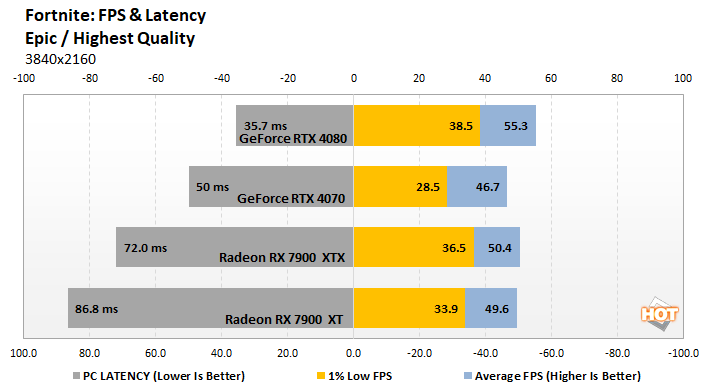
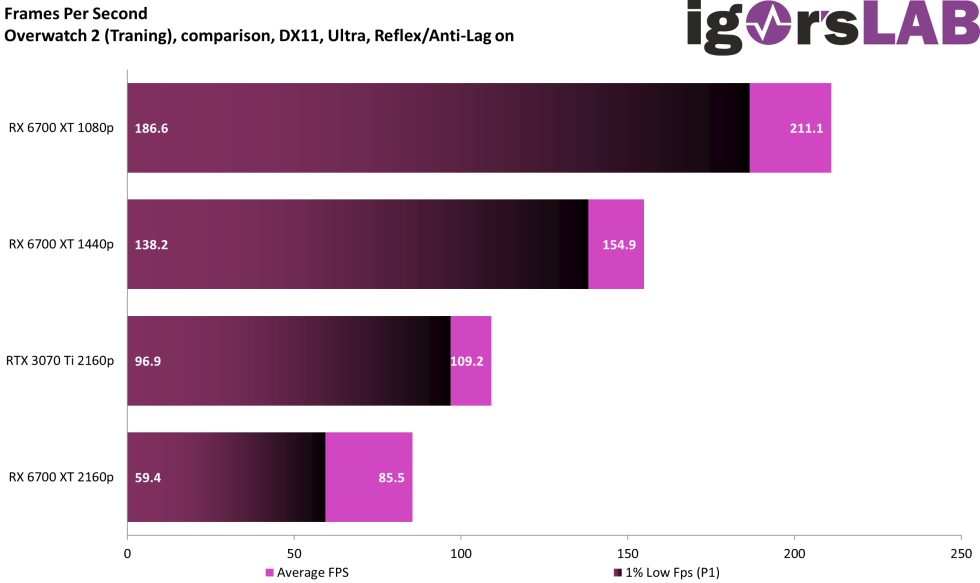
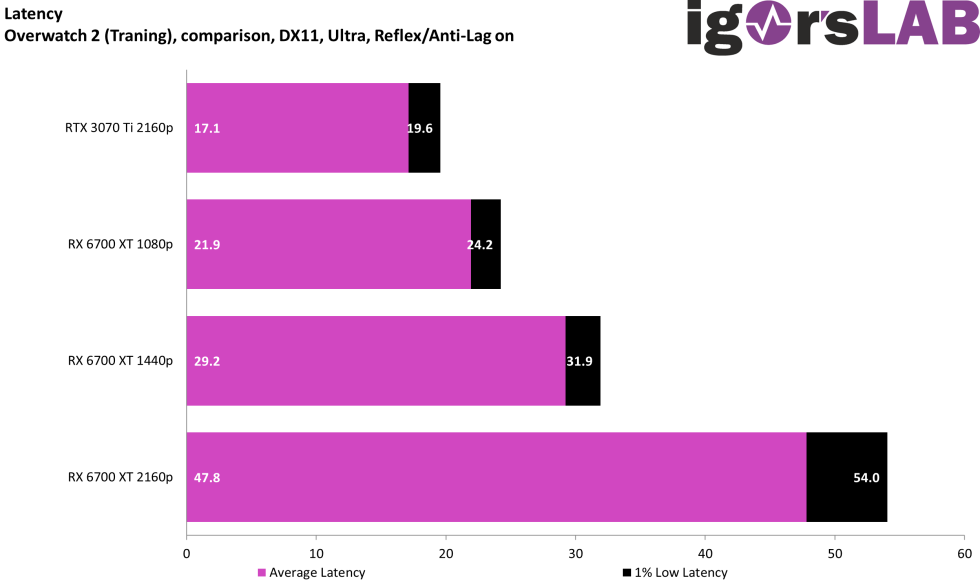

 My 4090 is ready. I can’t wait to see what this does for CP2077 in person. It already looks insane with path tracing but now the reflections are gonna be improved even more which is crazy when you think about it.
My 4090 is ready. I can’t wait to see what this does for CP2077 in person. It already looks insane with path tracing but now the reflections are gonna be improved even more which is crazy when you think about it.